The Missing Middle
AI discourse has split into two camps. Neither is measuring anything. That's the actual problem.
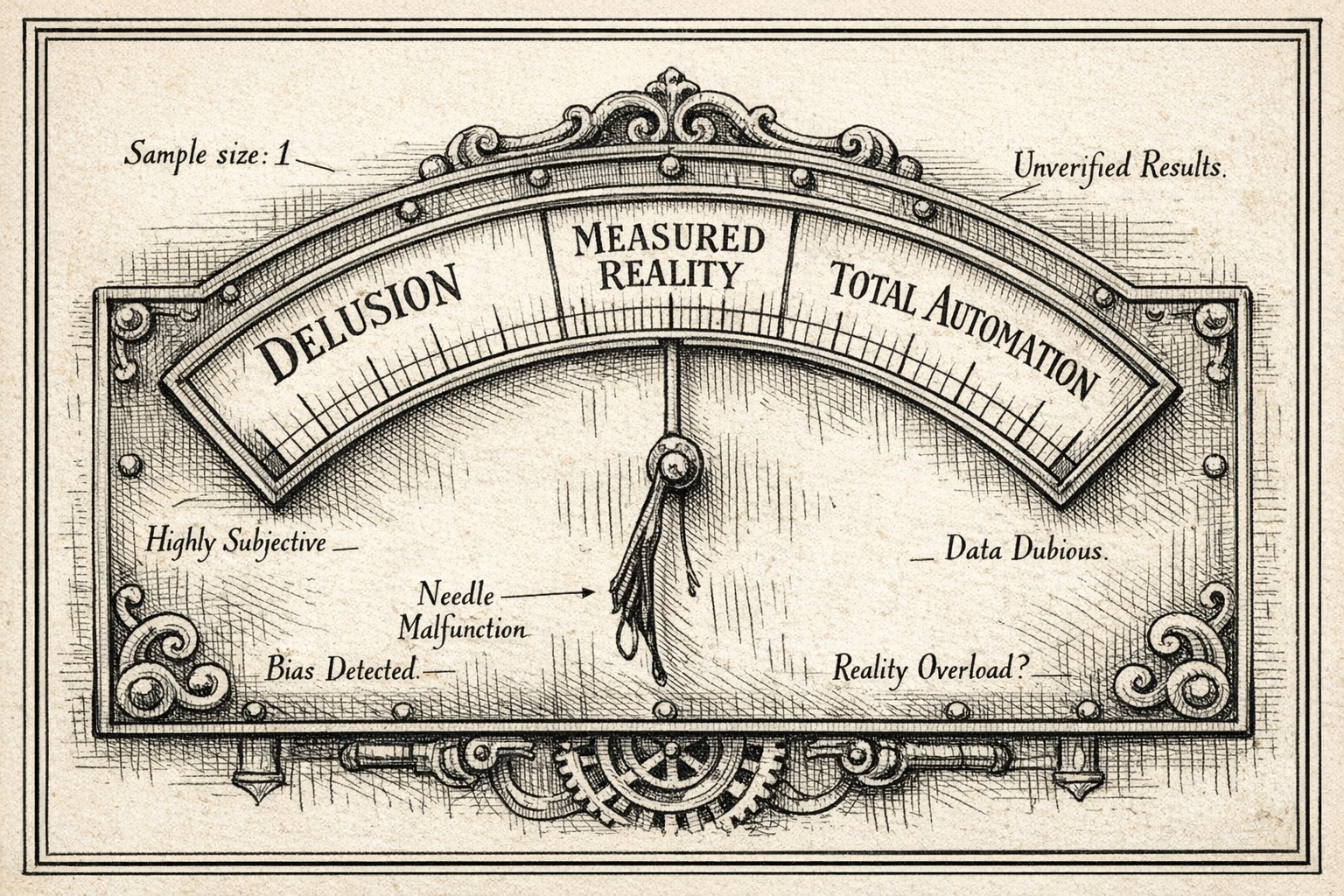
Table of contents
Microsoft's AI chief tells the Financial Times that most white-collar tasks will be fully automated within 12 to 18 months. Meanwhile, a recent study from the nonprofit METR found that AI actually made experienced software developers 20% slower. Depending on which headline you read first, you either updated your LinkedIn to "prompt engineer" or muttered something about tulip bulbs.
Maybe it's just the circles I move in or the media I consume, but I rarely see anyone advocating for the golden middle. It's either revolution or delusion, with very little room for "let's just look at the numbers." That bothers me. Not because both sides are wrong, they're both partially right, but because the space between them, where the useful decisions actually get made, feels almost abandoned.
I started thinking about this more concretely after watching a demo session by two very senior developers. Both experienced enough that they had nothing to prove. Both with stable careers and well-established reputations, so no anxiety pushing them in either direction. No financial incentives, no turf to protect. And yet, within the same presentation, one was clearly overhyped about AI's capabilities and the other was dismissive to the point of being closed off. Same room, same information, completely opposite reactions.
The easy explanations didn't apply. It wasn't about job security or technical ignorance. Something else was driving the split, and I wanted to understand what.
When I talk about the "missing middle," I'm not describing some philosophical compromise between optimism and pessimism. I mean something more mundane than that. Treat AI like any other engineering tool: form a hypothesis about where it helps, run a small experiment, measure what actually happened, and adjust based on evidence. No revolutions, no dismissals. Just evidence. It sounds obvious, and yet almost nobody I encounter is actually doing it.
Everyone has their own hype cycle
Most people in tech are familiar with Gartner's hype cycle, the familiar curve from innovation trigger through inflated expectations, disillusionment, and eventually productivity. Gartner's 2025 report places foundation models and generative AI firmly into the Trough of Disillusionment, which, if you follow the model, is actually a healthy sign. It's where realistic expectations start forming.
But here's the thing about that curve: it describes an aggregate. It's an average across an entire industry. Individual people don't travel through it in lockstep.
Each of us has our own personal hype cycle, shaped by our specific experiences with the technology. Someone who had a genuinely impressive early experience with AI-generated code might still be riding the peak of inflated expectations. Their colleague, who spent an afternoon debugging hallucinated API calls, may have jumped straight from the innovation trigger to the trough, skipping the peak entirely. Both of them are sitting in the same meeting, supposedly discussing the same technology, but they're actually arguing about completely different versions of it. They're arguing about their own experience.
This realization shifted how I see those polarized conversations. The two senior developers weren't irrational. They'd each had different encounters with AI, and those encounters placed them at different points on their personal curves. What looked like a disagreement about technology was really a disagreement about experience dressed up as one about facts.
Research on algorithm aversion supports this pattern. Dietvorst, Simmons, and Massey found that people lose confidence in algorithms far more quickly than in humans after seeing them make the same mistake, even when the algorithm still outperforms the human overall. One dramatic AI failure can catapult someone forward on their personal curve instantly, undoing months of positive experience. But the asymmetry cuts both ways. No single success seems to undo deep skepticism with equal force. The trust curve is genuinely lopsided.
On the other side, automation bias describes the opposite tendency: over-relying on automated recommendations without sufficient scrutiny. AI outputs arrive without the uncertainty cues we're used to in human interaction. No hesitation, no rephrasing, no hedging. The output looks polished, reads confidently, and that surface quality gets mistaken for reliability. Research has found that AI's lack of these natural uncertainty signals leads people to attribute higher confidence and trustworthiness to its outputs than may be warranted.
So we have two well-documented cognitive biases pulling in opposite directions, and where any individual person lands depends heavily on their disposition and their experience. It's no surprise that two reasonable people can look at the same tool and see completely different things. The question is what to do about it.
The confirmation machine
During the demo session I mentioned, the enthusiastic developer showed something that stuck with me. He'd used ChatGPT to build a case for a specific development approach, spec-driven development using a tool called Speckit. To support his argument, he showed the audience a ChatGPT conversation where he'd asked: "Why is speckit better than vibe coding?"
AI delivered exactly what was asked for. A well-structured, confident argument in favor of speckit. Compelling stuff. But here's the problem: if you turn the question around and ask "Why is vibe coding better than speckit?", you get an equally confident, well-structured argument the other way. The conclusion was baked into the question. The real answer, as with most things in software, is that neither extreme is optimal. There's a middle ground where some structure and some flexibility produce the best outcomes. But nobody was asking for the middle ground.
This is confirmation bias, but amplified in a way that feels genuinely new. Traditional confirmation bias requires effort. You have to seek out the blogs you already agree with, follow the people who share your views, selectively read the research that supports your position. With AI, the feedback loop is instant, feels authoritative, and it's personalized to your framing. You're not even aware you're doing it, because the tool just gave you what you asked for.
There's a deeper irony here. The person who uses AI most enthusiastically can be the one who understands its mechanics least. They've become so fluent with the tool that they've stopped noticing a fundamental property of it: these models are responsive to framing, not independent evaluators of truth. Knowing how to prompt well and understanding what the model is actually doing are different skills, and confusing them is where a lot of the overconfidence comes from.
The enthusiastic developer later admitted he hadn't actually reviewed the AI outputs in detail after building a whole application with the approach. He'd trusted the surface quality. In Ethan Mollick's framework for evaluating AI delegation, every AI task has three variables: how long the task would take you to do yourself, how likely the AI is to produce acceptable output, and how long it takes to evaluate what the AI produced. Skipping the evaluation step doesn't make AI more efficient. It just makes the equation invisible.
Adoption theater
The confirmation machine operates at the individual level: a person asks a leading question and gets the answer they wanted. But there's a collective version of the same pattern that I've started thinking of as adoption theater: the gap between the demo and the actual work.
We've all seen the demos. AI generates a website from scratch. AI builds an app from a single prompt. The audience reacts with genuine amazement, and to be fair, the output often is impressive at first glance. But anyone who builds software for a living watches these demos with a very different eye.
A typical data-driven web application, the kind of thing most enterprise teams actually build, has a visible layer of HTML and CSS that in my experience represents roughly 10 to 25% of the total effort. The remaining 75 to 90% is the invisible machinery that makes it actual software: state management, API integration, caching, error handling, authentication, accessibility, internationalization, performance on unreliable networks, and testing. For complex business applications with workflows, permissions, and audit requirements, the visible layer can shrink even further, sometimes to as little as 5 to 15%, with everything else making up the rest.
The template is the screenshot. The rest is the software.
When someone demos an AI-built application, what they're showing is overwhelmingly that visible layer. The audience sees the markup and the styling and says "it built a whole app!" But the part that makes software work, the part that's invisible by definition, is exactly where AI struggles most, because it requires deep contextual knowledge, business rules, and edge case thinking. The demo isn't just showing the easy part. It's showing the part that wasn't the bottleneck in the first place.
The social dynamics around this are painfully predictable. The person inside the bubble genuinely can't understand why professionals respond with polite restraint rather than excitement. They interpret it as resistance to change. Meanwhile, the professionals either don't have the energy to explain the gap or have learned that it's not worth the argument. The enthusiast walks away thinking people are stuck in the past. The professional walks away thinking the enthusiast is naive. Neither communicates honestly, and the polarization deepens.
The case for just counting things
So if individual impressions are unreliable and demos are misleading, what's left? Anyone who knows me professionally already knows my answer: you have to actually count things.
We've been experimenting with AI-generated test cases in our work. In the beginning, the results were clearly not good enough. Only a handful of usable tests out of 20 suggested, too atomic, too generic, details drifting from what was actually needed. Over time, with newer models and better-designed workflows, we've reached "this looks actually quite good" territory. The test cases read well, they're structured properly, and at first glance they seem thorough.
But that surface quality is seductive. When you investigate closely, you start finding that details are still drifting, crucial validations are missing, and stated check points don't quite hold up under scrutiny. No tester will approve anything without cross-referencing each stated validation point against the actual requirements. And that cross-referencing takes roughly as long as writing the tests from scratch would have.
Mollick's delegation framework helps make sense of why this matters. Even if the probability of AI producing acceptable output is reasonable, the process time, which includes the time to evaluate and verify, can eat the gains entirely. The enthusiast camp ignores evaluation cost. The skeptic camp ignores that the equation can change as workflows and models improve. Both are looking at partial pictures.
So we decided to try measuring it properly. Take a small sample of features where test cases had already been planned by humans, run them through our agentic workflow, and then simply count: how many tests were correct, how many had issues, and how many were unnecessary. Nothing fancier than that. The idea was that saying "70% correct, 20% with issues, 10% unnecessary" gives a very different foundation for discussion than saying "it seems pretty good" or "I don't trust it."
The foundation was right, but I'll be honest, we realized after the fact that the evaluation design had a significant flaw. The testers were judging both their own previously-written tests and the AI-generated ones. That introduces bias in both directions. Ownership bias makes people rate their own work more favorably. And depending on where each tester sits on their personal hype cycle, they might be too forgiving or too harsh on the AI output. What we thought was measurement turned out to be structured opinion gathering dressed up as data.
That was a humbling realization. But I think it's also the most important thing I could share in a post about the missing middle, because it demonstrates what the middle ground actually looks like in practice. It's messy. Your first attempt at being rigorous will have flaws. You'll realize the person judging should not be the same person whose work is being compared. OpenAI's GDPval study got this right by using separate expert judges for evaluation, something we should have done from the start.
The meta-lesson is that even "just measure it" requires measuring well. Independent evaluation, blind comparison where AI-generated and human-generated outputs are scored without knowing the source, or better yet, tracking which tests actually catch real bugs in production and letting reality be the arbiter. We're iterating on the design now. The first attempt wasn't wasted, it taught us where our own assumptions were, but it's a good reminder that the middle ground isn't automatically right just because it's in the middle. The value is in the discipline of trying to measure, honestly examining the results, and improving the approach when you find it lacking.
Where this leaves me
Neither camp is wrong in what they observe. They're wrong in their completeness. The enthusiast is right that AI can produce impressive output with remarkable speed. The skeptic is right that the output often doesn't survive contact with real requirements. Both are making claims based on what they can see, and what each can see is shaped by where they stand on their own curve.
The problem isn't the disagreement. Disagreement in the face of genuine uncertainty is healthy. The problem is the absence of empirical discipline in the space between. We've replaced "let's measure it and then decide" with anecdotes, demos, and vibes. Both camps are working with sample sizes of one, whether it's "I tried it and it was incredible" or "I tried it and it hallucinated basic facts."
Mollick makes the point that the people best positioned to use AI effectively aren't necessarily the most enthusiastic adopters but the domain experts who know what good output looks like. The skills often dismissed as "soft," knowing what to ask for, recognizing when something is off, having the judgment to correct it, turn out to be the hard ones.
I don't have a clean conclusion for this, because the topic resists one. If you ask me "why AI over traditional approaches?" I'll give you a good answer. If you ask me "why not AI?", I'll give you an equally good one. The useful question, the one almost nobody seems to be asking, is "where specifically, and how much?"
I think more teams should be running small, honest experiments with clear success criteria. Not to prove AI works or to prove it doesn't, but to find out where it helps, where it doesn't, and how to tell the difference. That's less exciting than either narrative. But it's the only approach I've seen that actually moves the conversation forward.